What is deep learning?
Deep learning is one of the subsets of machine learning that uses deep learning algorithms to implicitly come up with important conclusions based on input data.
Genrally deeplearning is unsupervised learning or semi supervised learning and is based on representation learning that is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task, it learns from representative examples. For example: if you want to build a model that recognizes trees, you need to prepare a database that includes a lot of different tree images.
The main architectures of deep learning are:
-Convolutional neural networks
-Recurrent neural networks
-Generative adversarial networks
-Recursive neural networks
I'll be talking about them more in later part of this blog.
Difference between machine learning and deep learning
Machine learning basically extracts the knowledge from the pre-processed data which has been trained on the model, and the user provides certain rules to the model to choose features accordingly and user can intervene if model gives any type of errors, but deeplearning is bit different.
In Deep learning, we require a large amount of data because it chooses features by itself and is computationally heavy to train and can draw accurate conclusions from raw data which removes our efforts to pre process our data but it takes much longer time to train, and you can't know what are the particular features that the neurons represent and it can be used in unexpected ways, and on the other hand Machine learning, we require small datasets as long as they are of high-quality then only model would be able to work, these models are not always heavy to compute, but user has to carefully train the model on pre-processed data and it does not take as much as time as deeplearning model and can be trained in a reduced amount of time, moreover logic behind the machine’s decision is clear and we choose the features on which model would be trained and algorithm is built to solve a specific problem.
Advantages of deep learning
Now that you know what the difference between DL and ML is, let us look at some advantages of deep learning.
In 2015, a group of Google engineers was conducting research about how NN carry out classification tasks. By chance, they also noticed that neural networks can hallucinate and produce rather interesting art.
The ability to identify patterns and anomalies in large volumes of raw data enables deep learning to efficiently deliver accurate and reliable analysis results to professionals. For example, Amazon has more than 560 million items on the website and 300+ million users. No human accountant or team of 1000 accountants would be able to track that many transactions without an AI tool.
Deep learning doesn’t rely on human expertise as much as traditional machine learning. DL allows us to make discoveries in data even when the developers are not sure what they are trying to find. For example, you want your algorithms to be able to predict customer retention, but you’re not sure which characteristics of a customer will enable the system to make this prediction.
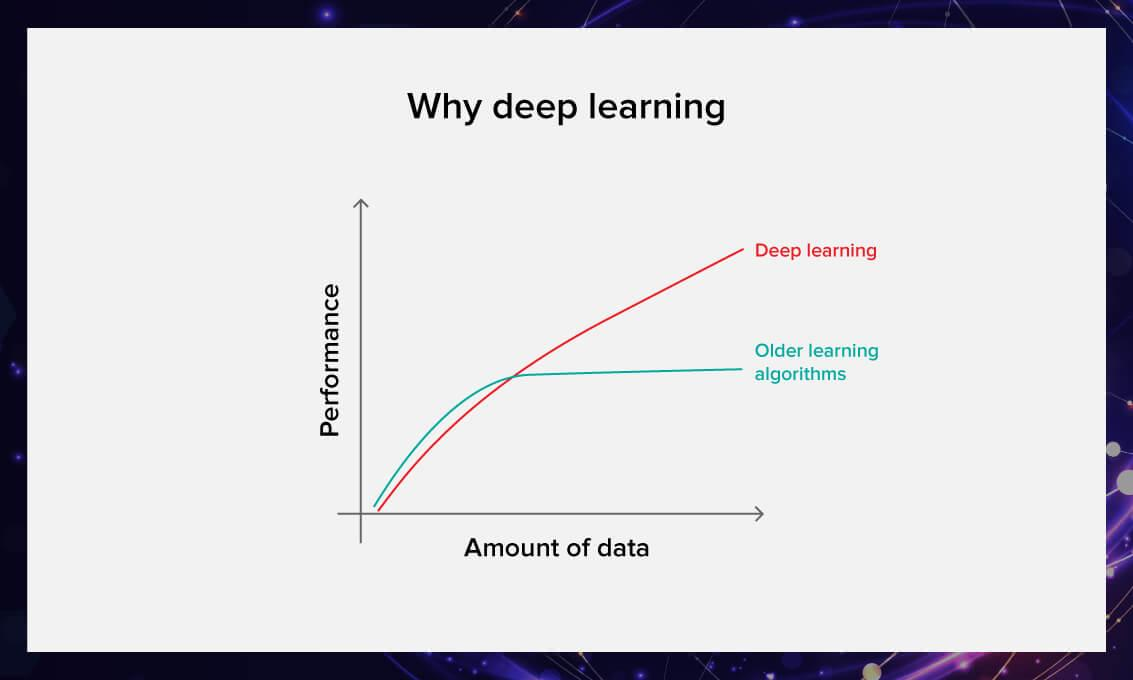
Problems of deep learning
Large amounts of quality data are resource-consuming to collect. For many years, the largest and best-prepared collection of samples was ImageNet with 14 million different images and more than 20,000 categories.
Another difficulty with deep learning technology is that it cannot provide reasons for its conclusions. Therefore, it is difficult to assess the performance of the model if you are not aware of what the output is supposed to be. Unlike in traditional machine learning, you will not be able to test the algorithm and find out why your system decided that, for example, it is a cat in the picture and not a dog.
It is very costly to build deep learning algorithms. It requires the user should have work with sophisticated maths. Moreover, deep learning is a resource-intensive technology. It requires powerful GPUs and a lot of memory to train the models. A lot of memory is needed to store input data, weight parameters, and activation functions as input propagates through the network.
Sometimes deep learning algorithms become so power-hungry that researchers prefer to use other algorithms, even sacrificing the accuracy of predictions.
How can you apply DL and NN to real-life problems?
Today, deep learning is applied across different industries for various use cases:
Speech recognition. All major commercial speech recognition systems (like Alexa, Google Assistant, Apple Siri) are based on deep learning.
Pattern recognition. Pattern recognition systems are already able to give more accurate results than the human eye in medical diagnosis.
Natural language processing. Neural networks have been used to implement language models since the early 2000s. The invention of LSTM helped improve machine translation and language modeling.
Discovery of new drugs. For example, the AtomNet neural network has been used to predict new biomolecules that can potentially cure diseases such as Ebola and multiple sclerosis.
Recommender systems. Today, deep learning is being used to study user preferences across many domains. Netflix is one of the brightest examples in this field.
What are artificial neural networks?
Artificial neural networks(ANN) and deep learning are often used interchangeably, which isn’t really correct. Not all neural networks are deep that is with many hidden layers, and not all deep learning architectures are neural networks.

What is ANN?
An artificial neural network represents the structure of the human brain modeled on a computer. It consists of neurons and synapses organized in layers.
ANNs can connect millions of neurons into a system, making them very successful in analyzing and even storing various kinds of information.
Let's see what activation function is as it will be very useful, Activation function is a function that maps a node’s inputs to its corresponding output.
Components of Neural Networks
A neuron or a node is a basic unit of neural networks that receives information, performs simple calculations, and passes it further.
All neurons in a net are divided into three groups:
Input neurons that receive information from the outside world
Hidden neurons that process that information
Output neurons that produce a conclusion.
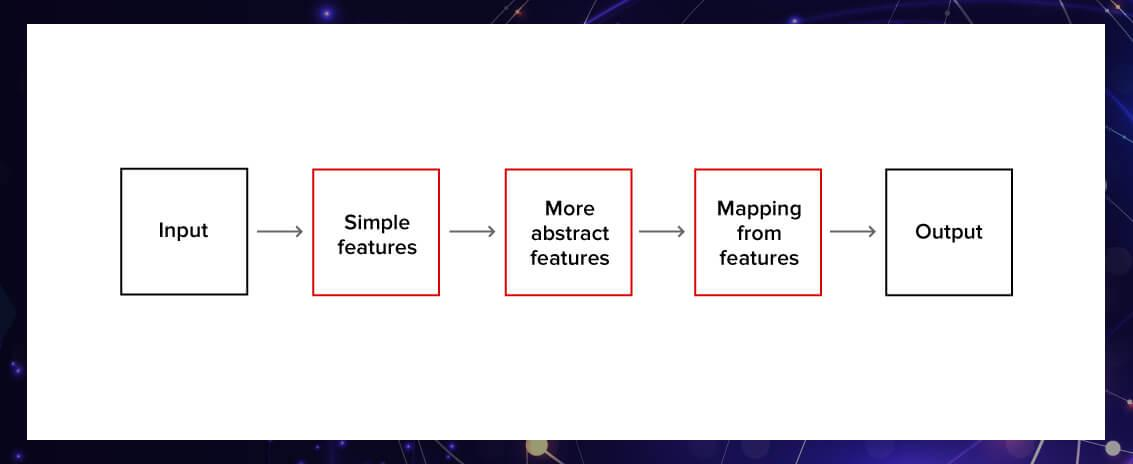
In a large neural network with many neurons and connections between them, neurons are organized in layers. There is an input layer that receives information, a number of hidden layers, and the output layer that provides valuable results. Every neuron performs transformation on the input information.
but how do neurons communicate? Through synapses.
Synapses and weights
Synapses connect neurons like power wires. Every synapse has weight. Weights also contribute to changes in the input information. The result of a neuron with a higher weight will dominate the next neuron, while information from a neuron with a lower "weight" will not be bypassed. It can be said that the weight matrix governs the entire nervous system.

How do you know which neuron has the biggest weight? During the initialization (first launch of the NN), the weights are randomly assigned but then you will have to optimize them.
Bias
A bias neuron allows for more variations of weights to be stored. Biases add richer representation of the input space to the model’s weights.
In the case of neural networks, a bias neuron is added to every layer. It plays a vital role by making it possible to move the activation function to the left or right on the graph.

It is true that ANNs can work without bias neurons. However, they are almost always added and counted as an indispensable part of the overall model.
How ANNs work
Every neuron process the input data to get the feature, Suppose we have five features and five neurons which are connected to those features.
Each of the neurons have their own weights which are used as weights of features, During the training of the model one has to provide weights to neurons which gives the result more accurate as dominant weights can suppress other weights
To get an output, every neuron has an activation function and these functions as a common can be expressed as F which describes the magic behind a neural network. There are many activation functions, the main difference is the range of values they work with.
How do you train an algorithm?
Neural networks are trained like any other model, If you want to get some results then give a model a good amount of data from which the network can learn. For example: if we want our model to classify between cats and dogs then provide our network plenty of images of cats and dogs.
Delta is the difference between the data and the output of the neural network. We repeatedly optimize the weights of the network until the delta is zero. Once the delta is zero or close to it, our model is correctly able to predict our example data.
Iteration
Iteration keeps the counter that how many times our neural network goes through our one training set, basically it's the total number of training sets covered by our neural network.
Epoch
The epoch increases each time we go through the entire set of training sets. The more epochs there are, the better is the training of the model. but if we go with very large values of epochs then model would be well trained and there are chances we could experience overfitting.
Batch
Batch size is basically the number of training examples or training dataset, higher the batch size the more our model would be precise with output and more computational we'll need.
What about errors?
Error is the deviation between our expected and actual output and error should me be minimised after every epoch and if it's not happening then we are doing something wrong
The error can be calculated in different ways, but we will consider only two main ways: Arctan and Mean Squared Error.
What kinds of neural networks exist?
There are so many types of neural network and it is nearly impossible to go through all.
Recurrent neural networks
A recurrent neural network can process through texts, videos, images and become more precise every time because it remembers the results of the previous iteration and which uses the output of previous iteration and remembers it too.
Recurrent neural networks are widely used in natural language processing and speech recognition.
Convolutional neural networks
Convolutional neural networks are the major of today’s deep learning and are used to solve the majority of problems.
Let’s see how they work. Imagine we have an image of Pikachu from Pokemon. We can assign a neuron to all pixels in the input image but there would be a problem if we connect every pixel to every neuron than we'll get lot's of weights to consider and it will be overwhelming to differentiate between dominant weights and other one's and moreover it will take high computational operation and will take very long time.

Therefore, programmers came up with a different architecture where each of the neurons is connected only to a small square in the image. All these neurons will have the same weights, and this design is called image convolution. We can say that we have transformed the picture, walked through it with a filter simplifying the process. Fewer weights, faster to count

Feed-forward neural networks
Feed-forward neural networks is the simplest neural network problem and it doesn't have any memory of last iteration. That is, there is no going back in a feed-forward network. In many tasks, this approach is not very applicable.
Feedforward neural networks can be applied in supervised learning when the data that you work with is not sequential or time-dependent. You can also use it if you don’t know how the output should be structured but want to build a relatively fast and easy NN.
What kind of problems do NNs solve?
Neural networks are designed to solve complex problems similar to those of the human brain. The most common uses for neural networks are:
Classification. Neural network label the data into classes by implicitly analyzing its parameters. For example, a neural network can analyse the parameters of a student such as age, intrest, previous projects and decide whether to loan them money.
Prediction. The algorithm has the ability to make predictions. For example, it can tell wether the same government would come or not according to past work, tweets about the government by other people.
Recognition. This is currently the widest application of neural networks. For example, we can detect trees from the forest and create a bounding box around them.
Summary
Deep learning and neural networks are useful technologies that expand human intelligence and skills. Neural networks are just one type of deep learning architecture. However, they have become widely known because neural networks can effectively solve a huge variety of tasks and cope with them better than other algorithms.
Comments
Post a Comment